Frances Madden (orcid.org/0000-0002-5432-6116)
Posted 26 February 2021
So far we have used these blog posts to cover different types of collection information which might benefit from persistent identifiers as well as how the various institutions involved with the project which have not yet implemented persistent identifiers might benefit from them. On this occasion we turn to one of the aggregators of UK GLAM collections, the Archives Hub, to find out how they use identifiers and how they might assist them in the future.
Aggregation and a ‘national collection’
As the Towards a National Collection programme is working towards developing a "unified virtual 'national collection'", therefore an aggregator has the unique perspective on the barriers which exist between collections and the issues encountered when trying to join them together. Persistent unique identifiers can play a crucial role in combining collections in a sustainable way so we wanted to get the view of the Archives Hub on this work.
About the Archives Hub
According to its website, 'the Archives Hub brings together descriptions of thousands of the UK's archive collections. Representing over 330 institutions across the country, the Archives Hub is an effective way to discover unique and often little-known sources…often representing collections being made available for the first time.' The Archives Hub system is based on CIIM, a product supplied by Knowledge Integration, which is also being implemented by the National Gallery to support the integration of their collections across different systems.
Archives across the UK contribute to the Archives Hub either via filling in the Archives Hub own EAD (Encoded Archival Description) Editor form, through exporting from an existing archive management system or harvesting via an OAI-PMH endpoint. The Hub maintains a variety of methods to support the wide range of archives with which it works, including some very small and under resourced repositories. The staff at the Archives Hub have a large amount of expertise in rationalising and working with data from a wide array of systems and making it interoperable with their own system. As a result of this they accept data in a range of formats so long as it is compatible with EAD.
Names project
Recently the team began working on a project with Knowledge Integration around names within the Archives Hub. As the Archives Hub was officially launched in 2001 and it doesn't have any standardised use of names in the data it holds but would like to rationalise them to aid resource discovery. EAD/ISAD(G) does not harmonise the fields with index terms, which are generally the links to authority files within a collection. This means that often Creator names will appear in an array of formats, which are different from the index term which will be created in a standard format and include useful information such as date and perhaps epithet.
For example this record contains a Creator written in the format first name, surname. At the bottom of the page, it contains index terms which format the same name as surname, first name, dates, epithet. Within one record it is obvious that these two names are the same, but trying to apply automatic matching protocols across hundreds of thousands of names from hundreds of collections, it is not so clear. As Creator is a free text field, sometimes during harvesting the format is not standardised meaning it can include terms such as ‘various’ or additional text such as ‘Created by’ or ‘Possibly’ is included before a proper name.


Jane Stevenson from the Archives Hub has blogged extensively about the project and describes many of the issues encountered when trying to algorithmically de-duplicate hundreds of thousands of names. Through a lot of hard work, they have developed a process to standardise name formats across the metadata they hold. Once that has been done they can begin the process of deduplication. It was noted that once identifiers are in use, format matters less because you can connect different entities together with a 'same as' relationship, regardless of how the name string itself is formatted. This is true not only for names but for any type of entity, such as location, subject or organisation etc. Once the identifier is a constant connection it can be used in multiple systems. The Archives Hub's own cataloguing tool encourages VIAF IDs to be added to names by providing a lookup to VIAF. Any names with the VIAF ID will be uniquely identifiable, however they are structured.
The names project has also highlighted another issue mentioned in the previous blog post about persistent identifiers for location data - how to deal with uncertainty. For many of the names held within the Archives Hub, this may be the only mention of them. Traditional authority files are maintained by a single institution and can often lack detail due to the limited sources and resources available within the archive. Key information may be lacking from known individuals and this results in a large number of records from different organisations with sparse metadata, meaning it is difficult to make definitive matches across collections. However by making that information available, one invites these connections to be made by others.
Links to digital content
The Archives Hub provides links to digital content held within contributing archives as well as supporting collection information.
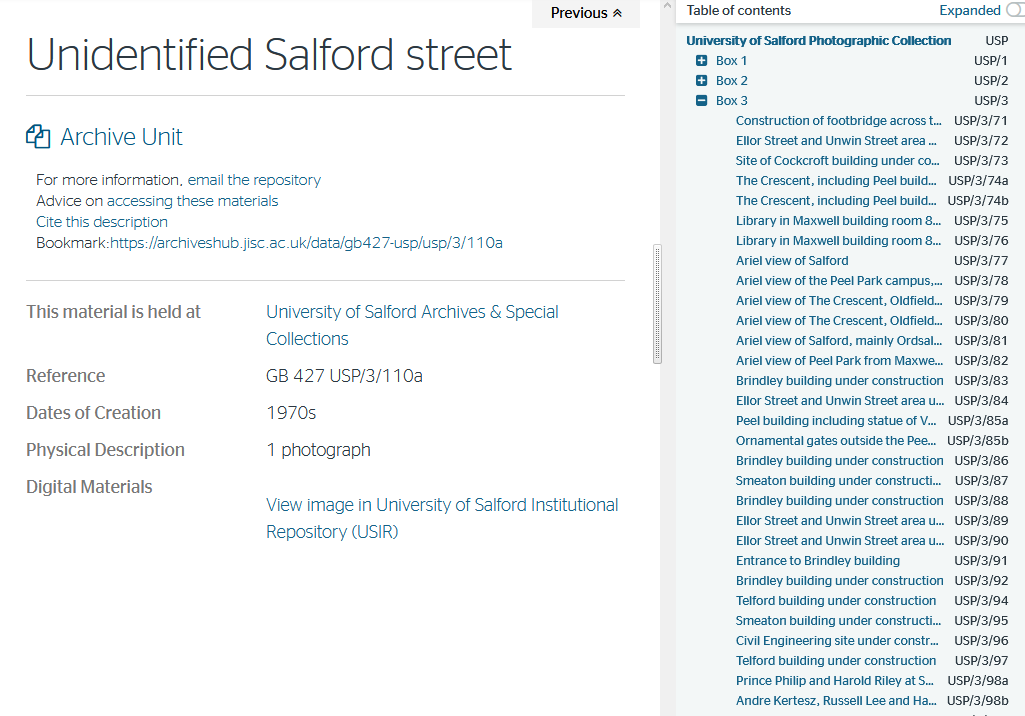
This can be done in a couple of ways, the first is where the contributing organisation provide a link which is displayed on the Archives Hub, as in the screenshot above. These links would ideally be persistent, but in many cases they break. Links to collection items frequently break and the Archives Hub has recently agreed a link check service with their system supplier to ensure the continued access of collections. This is a clear demonstration of how persistent identifiers help in building robust long-lasting connections to collection information.
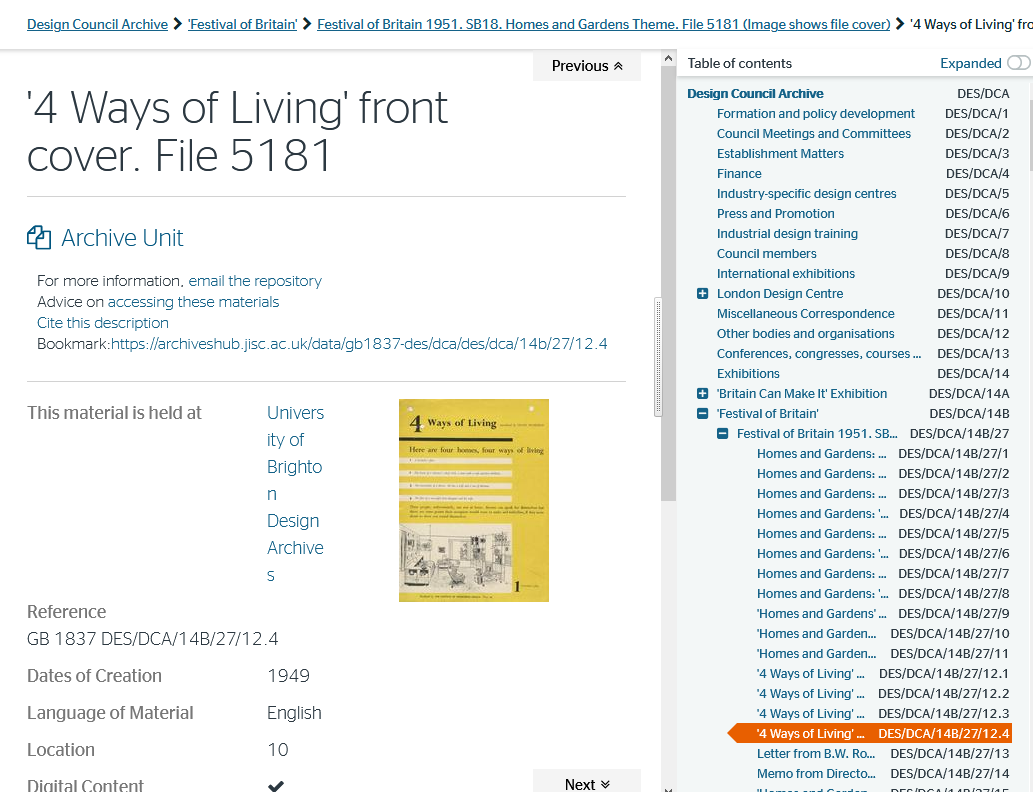
The Archives Hub can also display images by importing them using the URL and storing them locally, as in the screenshot below and there have been discussions about making that a more permanent feature of the service, offering a repository type function to Archives. This method does ensures the image remains available, but ironically the image may then be removed from the URL but still be viewable on the Archives Hub.
Identifiers for discovery
Records in the Archives Hub are assigned opaque URIs which can be viewed in the browser bar of a record. The Archives Hub also creates 'bookmark' links to aid citation of collections. This follows a standard format of ‘https://archiveshub.jisc.ac.uk/data/CountryCodeRepositoryCode-Reference’, such as ‘https://archiveshub.jisc.ac.uk/data/gb12-ms.add.9267’. These contain semantic information and are human readable to an extent. The country code is always 'GB’ or IM for the UK or Isle of Man. The repository code will correspond to the ARCHON code assigned by the National Archives for that particular repository. The reference will be the same as that used by the archive. These are regarded as user friendly for archivists and researchers as the semantic information within them can be understood by those familiar with the collections, however this relies on the reference being persistent, and that is not always the case. Changes are not frequent but do occur, mostly due to items being moved within the hierarchical structure of archive collections, therefore changing their reference number.
For example, if the photograph listed above was moved from box 3 to box 2 the reference would change from GB 427 USP/3/110a to GB 427 USP/2/XXX, where XXX is the number of the item in the box. This is unlikely to happen in collections which have already been catalogued to item level but it could occur, for example, where boxes or files were rearranged to suit a particular theme.
Repository codes can also sometimes change for collections where collections are merged. For example, Manchester University Archive (GB 133) holds both the University Archive and the Methodist Archive (GB 135) which had two different repository codes but these were combined under the Manchester University (GB 133) code which meant that those links needed to be changed.
Thus far the Archives Hub has changed the bookmark links to match with the most recent version meaning older links would break. Redirects could be put in place to make sure the link continues to remain resolvable but where items have been reclassified within the hierarchy, a reference could be reused for a different record. These links do not have any governance that they will be persistent but best efforts are made to do so where possible. The longevity of the Hub means that they have encountered issues which occur over time and which may not have yet been encountered by more recent implementations. As the Archives Hub is an aggregator of metadata, they cannot create persistent links themselves as they do not have the capability of ensuring the accuracy and quality of the metadata they hold.
Low barrier to entry
The Archives Hub’s broad experience aggregating data from diverse collections provides some useful insights into any type of persistent identifier implementation or recommendations which could feed into the Towards a National Collection programme. They have prioritised keeping the user base as broad as possible and making sure anything they develop works for all of the contributing archives. This can mean that progress is slow and solutions may not have as many features as what larger, better-resourced organisations could accommodate, however, it does mean that a huge array of collections are more discoverable and accessible.
For the Heritage PIDs project, it is a salient reminder to think about the requirements we are developing for the sector and making our project’s recommendations and guidance as inclusive as possible. This does not mean that institutions should not try to make their collections as persistently, globally identifiable and resolvable as possible, but it does mean that any tools developed in support of a national collection should be lightweight and implemented by collections easily within minimal financial and human resources.